本篇我們將會介紹關於Azure的儲存服務,從Azure SQL DB Managed Instance, Azure VM中的 SQL Server, Azure table storage 與 Cosmos DB等。同時我們也會學習到如何設計Azure Storage solution是具資料加密的功能。
本篇將讓我們在Azure Cloud具有下列能力:
Azure SQL DB的設計
關聯式資料是具有共用結構描述的結構化資料類型。 資料會儲存在具有資料列、資料行和索引鍵的資料庫資料表中,用於電子商務網站之類的應用程式儲存體。下圖為在Azure Cloud中可供我們選擇的部署模式,分別是IaaS (SQL Virtual Machine), PaaS(Managed instances, Databases)。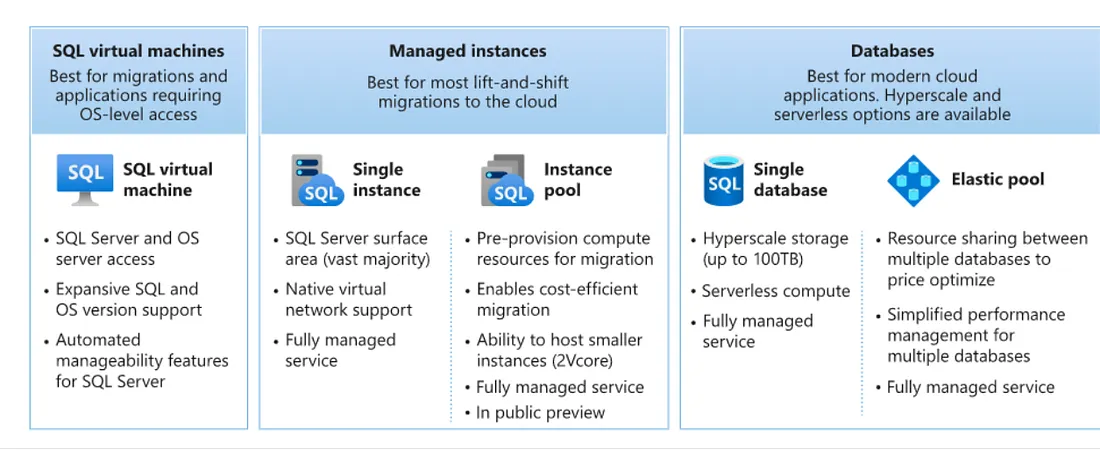
Azure SQL Database
這是Azure的PaaS部署模式。 它是一種高度可擴展的RDBMS服務,具有高可用性的 SLA。
SQL DB也是唯一支援以下的部署選項:
SQL Database 有兩個主要定價選項:DTU 和vCore。 serverless選項也適用於單一資料庫,可針對非預期的workloads進行AutoScaling
Azure SQL DB還可以Azure其他的服務整合,如 Azure Data Factory 與機器學習。詳細的功能如下圖所示
SQL elastic pools
當我們要使用Azure SQL DB時,我們可以建立 SQL elastic pool。這個部署方式讓我們有"一組運算與儲存的資源"可以share我們所有在這個pool裡的Database。每一個DB可以使用這一個pool中它們所需的資源(在我們的限制之下),根據現有的負載。詳情可以參閱Azure 文件。
Azure Database的選購模型
Azure SQL DB有三種定價方式分別是:
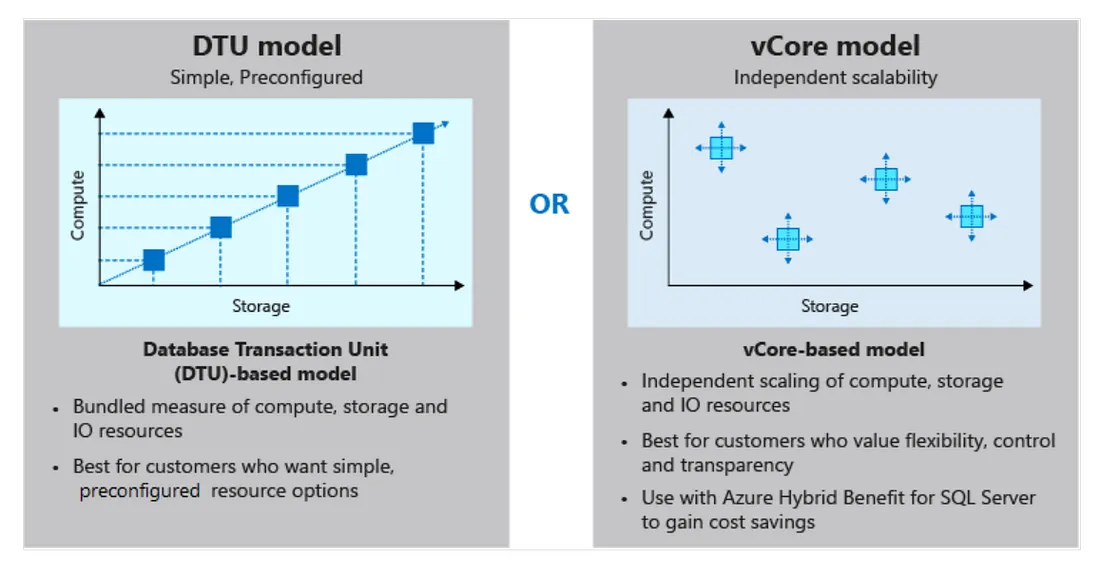
DTU就是將DB會用到的所有資源(包含 compute/storage/IO)結合起來.DTU模式是一個簡單且"預先配置(先圈資源,不管你有沒有用到)"的購買選項.但這個無法用在 SQL managed instance.而vCore的概念就回到我們在VM架設SQL Server,每個SQL instance有著獨立的 compute/ storage/ IO resource,是不能被共用的.
Serverless 模式是 Azure SQL DB中單一個DB的compute tier。 它會根據工作負載需求進行autoscaling compute,並僅按使用的計算量計費。 下圖為一個範例示意圖。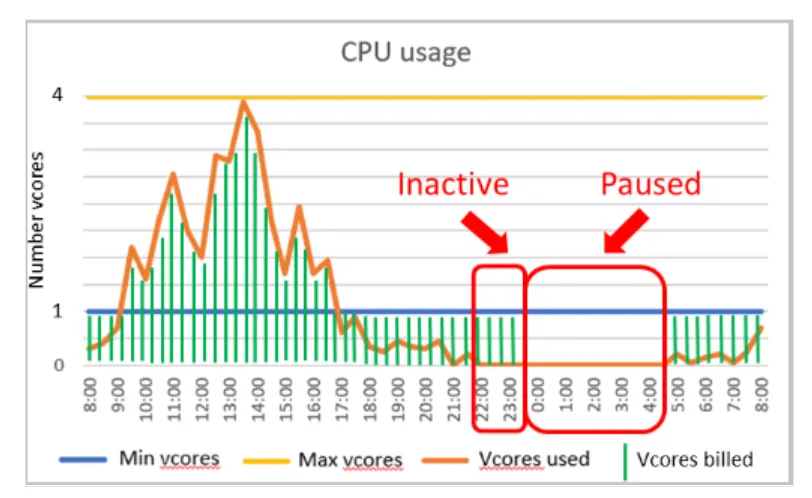
如果我們的DB是用在Production,哪就會推薦使用基於 vCore 的模型,因為它允許我們獨立選擇compute和storage resource。這種方式不會讓共用的resource影響到Production.而 DTU 的模式,其資源是分享的所以適合用在開發 /測試的環境中,因為使用效率可以最大化就算使用量到頂了影響層面也不會太大。
vCore 模型還允許我們使用適用於 SQL Server 的 Azure Hybrid benefit and(or) 預留容量(預付費用)來節省費用。 但這些option在 DTU model中是不能使用的。
Azure Database service tiers
根據效能、可用性和存儲需求,Azure 在下表討論的 vCore model中提供了三個DB service tier。
Azure SQL DB和 Azure SQL managed instance確保 99.99% 的可用性,即使在基礎設施掛掉的情況下也是如此。
Azure SQL DB和 SQL managed instance可以使用的service tier是 — General purpose和business Critical。 Azure SQL DB還多一個Hyperscale service tier。
對於General Purpose service tier, primary replica 使用locally attached的 SSD 作為 tempdb。 data和log file存儲在 Azure Premium storage中。 然後將backup file存儲在 Azure standard storage中。 發生fail over時,Azure service fabric將尋找具有備用容量的節點並啟動新的 SQL Server instance。 然後將DB file attach,進行recovery,並update gateway以將Application指向新節點。(如下圖)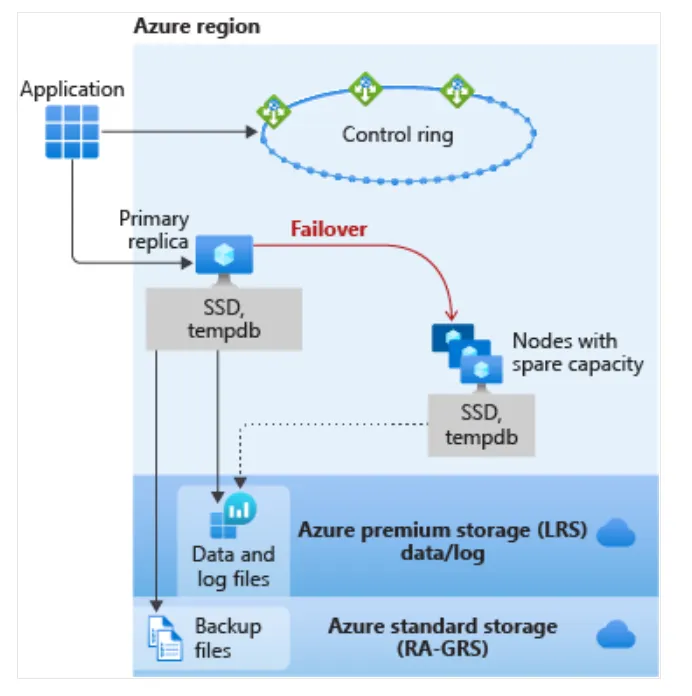
Business critical架構適用於需要"低延遲和最短停機時間"的重要系統。 Business critical就像在背景部署 Always On availability group(AG)的功能,data和log file的存儲方式與General purpose不同,因為它們存儲在direct attached的 SSD 上。
在Business critical場景中,data和log file都在直接掛載的 SSD 上運行,這降低了網路延遲。 在此架構中,有三個secondary replicas。 如果發生任何類型的故障,fail over到secondary replica會很快,因為資料已經存在並且SSD已經被attach了。
Azure SQL DB Hyperscale是一項全託管服務,可通過將存儲快速擴展到 100 TB 來適應不斷變化的需求。 靈活的雲原生架構允許存儲是根據需求增長的,並使我們能夠幾乎即時備份資料並在幾分鐘內恢復我們的DB— — 無論data operation的大小如何。
Hypersacle 提供快速DB restore、快速scale out和scale up。 Hypersacle DB會根據需求增長 — 我們只需為使用的容量付費。
下圖說明了Hypersacle架構中不同類型的節點。計算節點是relational engine所在的地方,也是SQL語言、query和transaction processing運作的地方。運算節點具有基於 SSD 的cache(標記為 RBPEX — Resilient Buffer Pool Extension)。有一個或多個secondary compute nodes充當hot standby node來進行fail over,以及充當read-only compute nodes。Page server是代表scaled-out storage engine的系統。Pager server的工作是按需求將DB page提供給compute node。Page Server還維護涵蓋基於 SSD 的cache以提高效能。Log service接受來自primary compute replica的日誌記錄,將它們保存在durable cache中,並將日誌記錄轉發到其餘compute replicas(以便它們可以update cache)以及相關的Page server,因此Data可以在那裡被update。這樣,來自primary compute replica的所有資料更改都會通過日誌服務傳送到所有的secondary compute replicas 與page servers。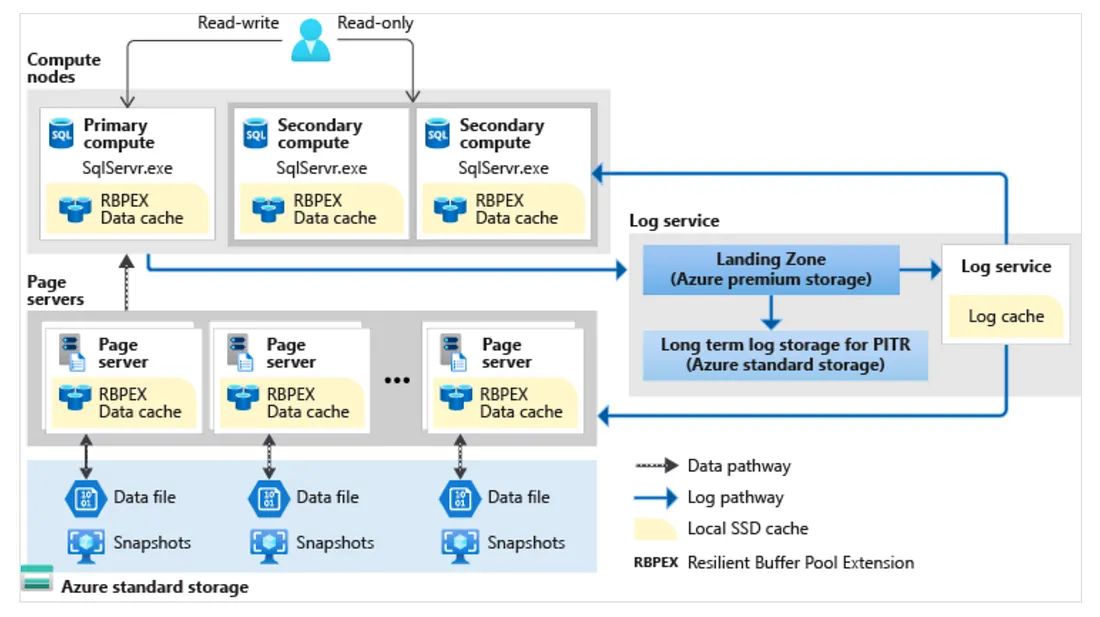
Azure SQL Managed Instance
Azure SQL managed instance是 Azure SQL 的 PaaS 部署選項。 它提供了一個 SQL Server insatce,但消除了不需要管理VM的工作。 SQL Server 中大多數功能在 SQL managed instance都是可以使用的。
SQL managed instance適合希望使用instance scope的功能並希望在不重構Application的情況下搬到 Azure。SQL Managed Instance使用vCore模式。 我們可以定義配置給Managed Instance的 CPU 核心數和儲存體上限。 Managed Instance內的所有DB會共用配置給Instance的資源。
SQL managed instance scope的功能包括:
假設我們有多個用於不同類型資料的mainframe applications。我們希望整合這些Application可以看到overall view。 另外,我們 想要一種減少overhead的方法。由於我們使用 很多SQL Server 功能,我們(IT 部門)選擇遷移到 Azure SQL managed instance。 我們能夠順利移動很大的資料並獲得以下效益:

Azure SQL Managed Instance 的擴展(Scalability)
SQL managed instance使用 vCores model,我們能夠定義分配的instance的最大 CPU core和最大存儲空間。關於SQL DB與SQL managed instance的功能比較可以參考Azure的文件.
在VM上的SQL Server 設計
將SQL Server運行在我們需要自行管理的VM上意味著:
我們使用一個醫療業的案例(如下圖)。 為了頻繁轉換其Application並安全可靠地託管它們,我們希望快速遷移到 Azure。這個案例中我們可以使用 Azure Site Recovery 將在大約 1,000 個 VM 上運行的數十個Application遷移到 Azure。
PS. 如果我們在地端機房已經有採購Windows Server與SQL Server 的license,我們可以使用Azure Hybrid Benefit.
到此我們可以來比較上述所提的三種SQL Server的部署模式有何不同(如下表)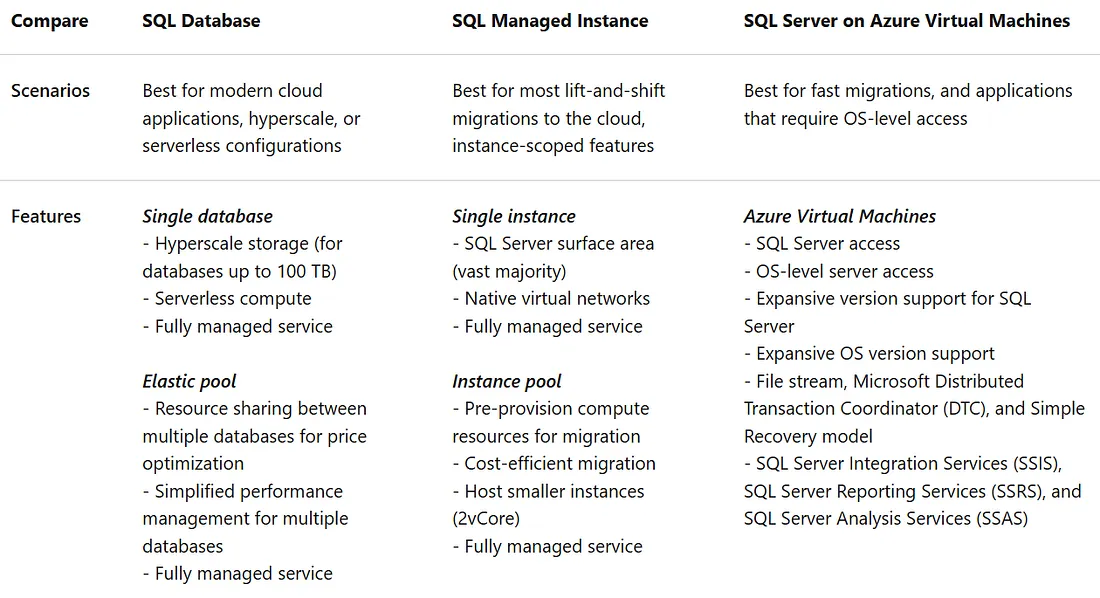
Azure SQL Database的動態擴展性(Scalability)
如果我們希望將SQL server遷移到雲端,必須選擇一種低延遲和高可用性的DB解決方案來存儲關聯式資料。 我們可能決定實施 Azure SQL DB,這是一項完全託管的服務,在Availability Zones的Business critical service tier中具有 99.995% 的可用性 SLA。
我們的下一個決定是如何處理可擴展性。 就是relational DB的可擴展性。 我們必須設計一個可動態擴展的解決方案,以處理工作負載。 我們的解決方案應該能夠隨著時間的推移處理越來越多的request,而不會對可用性或效能產生負面影響。 在這種情況下,我們要怎麼做呢?
Azure SQL DB讓我們能夠以最短的停機時間更改分配給我們的DB的資源,包括:
Azure SQL DB的動態擴展讓我們能夠:
Azure SQL DB的擴展型態
下圖說明的scale up and scale out的模式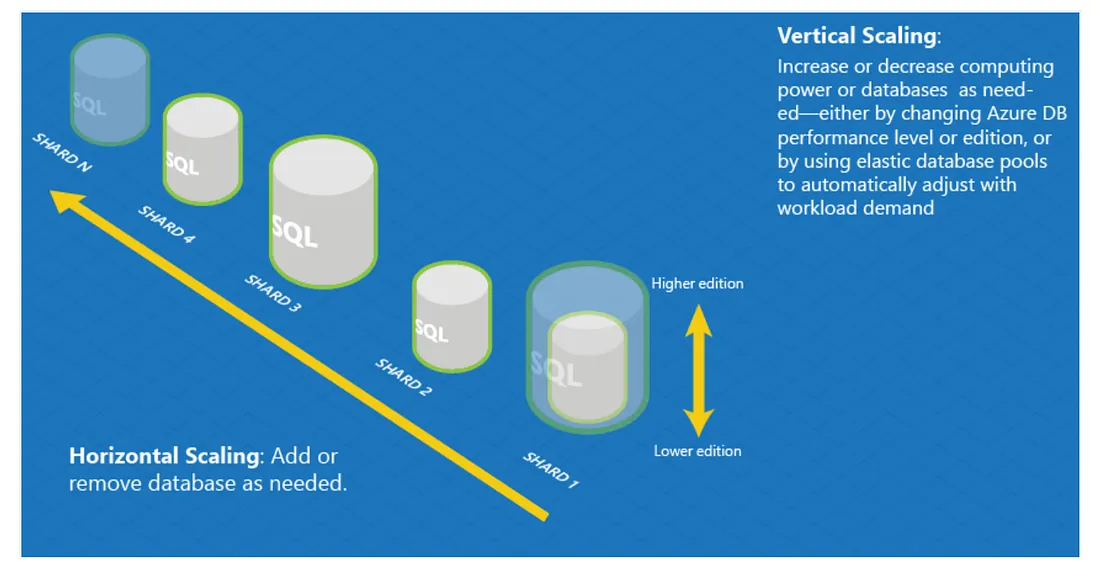
Vertical Scaling(Scaling up)解決方案設計
假設我們的公司在全球的業務經歷快速增長,需要為每個國家/地區維護和擴展單獨的 Azure SQL DB。 但是,增長速度和DB負載差異很大,因此資源需求無法預測的。 我們該如何管理擴展(scaling)以滿足組織的業務需求呢?
在這種情況下,最好選擇 SQL Elastic pools來擴展、管理效能和管理一組 Azure SQL DB的成本(如下圖)。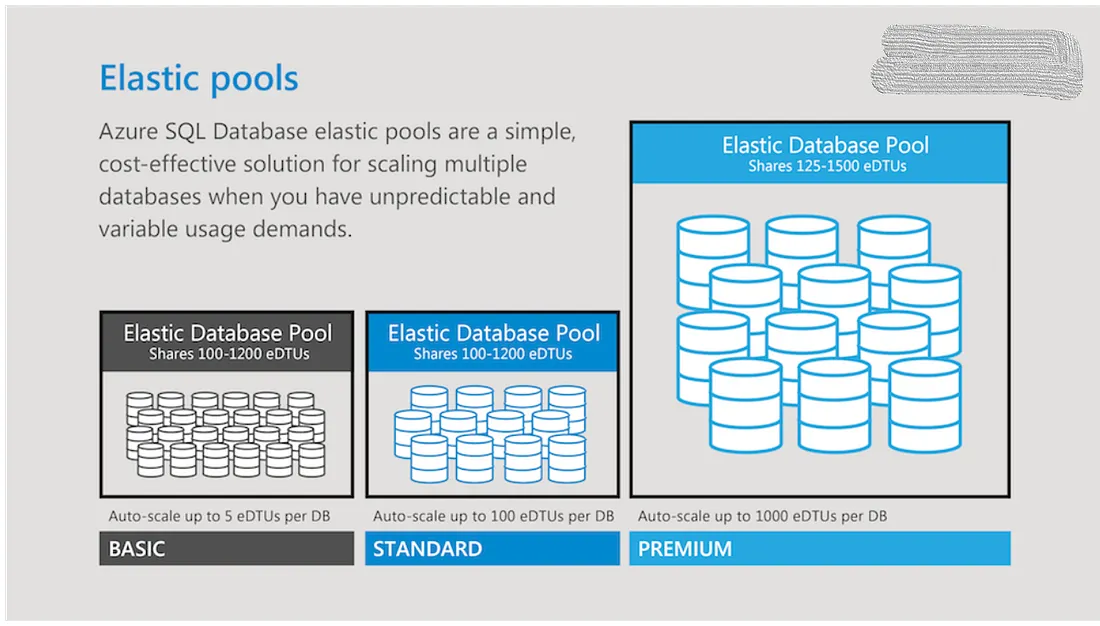
上圖顯示了 SQL Elastic pools和不同service tier的scaling capability。 pool中的DB共享分配的資源。 在平均使用率較低但很少出現高使用率峰值的情況下,我們可以在pool中分配足夠的capacity來管理group的高峰。 要正確配置 SQL Elastic pools以降低成本,必須選擇正確的購買模型和service tier (基於 DTU model 的basic/standard/permium或基於 vCore model 的general purpose or business critical)。更多的 SQL elastic pools可參考此篇文件。
Horizontal Scaling解決方案設計
這裡有兩種水平擴展:
假設我們 我們有一個Application要存取 OLTP來更改裡面的資料,以及使用 Analytics application access read-only workload來呈現資料可視化。 我們可以做些什麼來分擔一些運算能力,從而不影響Application的效能?
一個簡單的方法是為某些service tier使用pre-provisioned的read scale-out功能。 read scale-out功能允許我們使用其中一個read-only replica的運算能力來分擔real-only的作業,而不是在read-write replicas上運行它們。 這樣,一些real-only workload可以與read-write workloads 分離,並且不會影響它們的效能。
下表呈現了 Azure SQL DB 和 Azure SQL managed instance的Read Scale-out provisioning: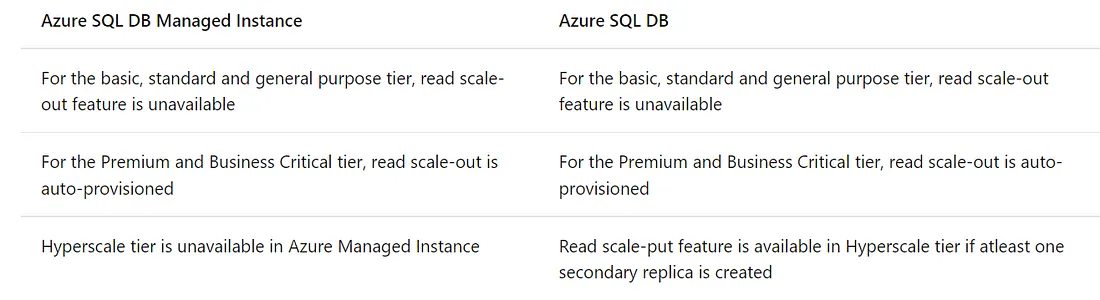
而下圖則呈現了business critical service tire的read scale-out的架構: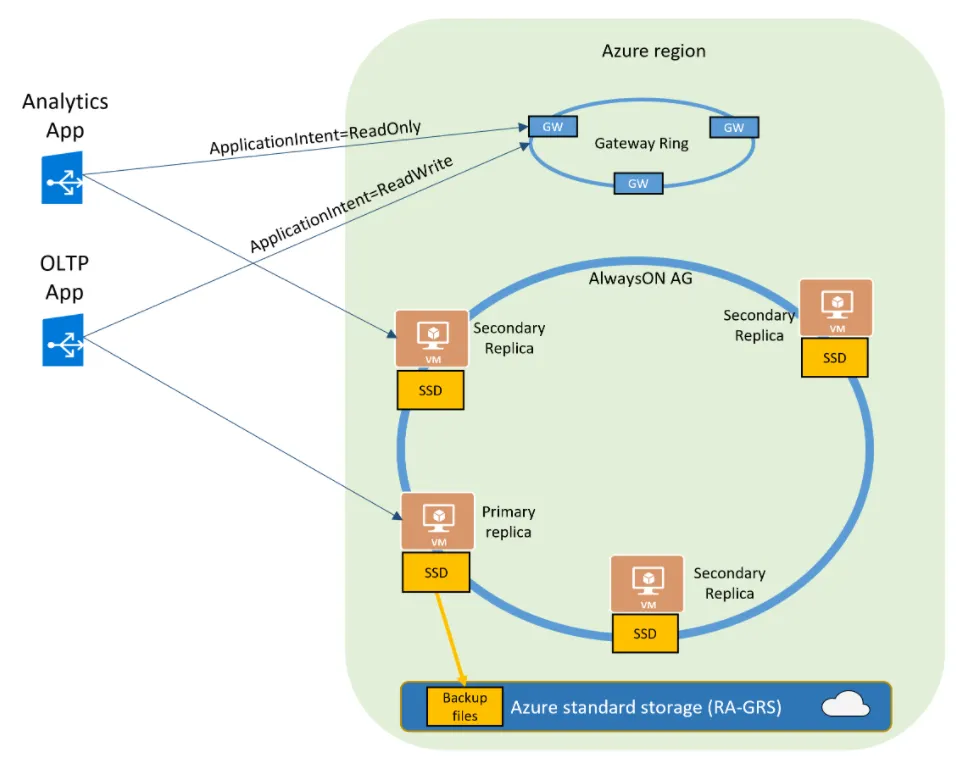
在下圖Business Critical場景中,data和log files都在直接掛載上的 SSD 上運作,這降低了網路延遲。在此架構中,有三個secondary replica。如果發生任何類型的故障,fail over到secondary replica會很快,因為該replica已經存在並且資料已經直接掛載上的 SSD的。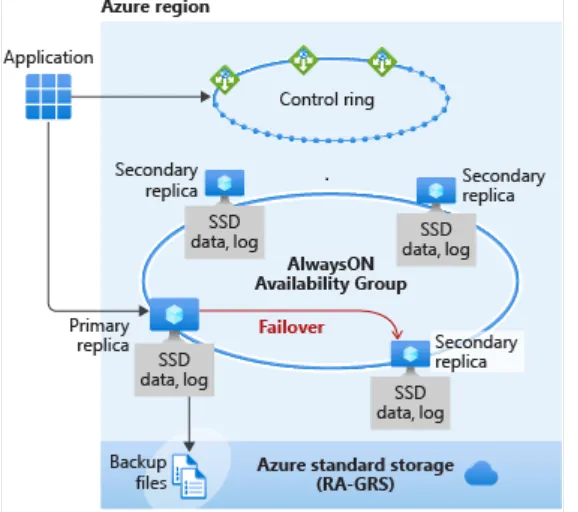
在上面顯示的 Azure SQL DB 或 Azure managed instance 的 premium/business critical tier的高可用性架構中,我們可以看到它被配置為一個 Always On Availability Group,用於DR和Application的高可用性。有一個主要的read-write replica和幾個secondary read-only replicas。secondary replicas與primary replicas具有相同的compute size。我們設置connection string option來決定connection是路由到write replica還是read-only replica。
我們可以使用以下方法disable和re-enable Premium or Business Critical service tiers中的單一個DB和elastic pool DB的read scale-out:
PS:
在primary replica上所做的資料異動同步傳送到read-only replicas。 在連接到read-only replicas的session中,read始終是transactionally consistent。 但是,由於資料傳送延遲是變動的,因此不同的replica可以在相對於primary replica和彼此略有不同的時間點return data。
Sharding
假設我們有一個Application,這個Application的transaction throughput超出了我們給予對應DB的capacity。 我們如何配置DB以提高效能和可用性呢?
上述情況的一個可能解決方案是用sharding來進行 Horizontal Scaling 或horizontal partitioning。 這是一種將大量相同結構的資料分佈在多個獨立DB中。
Sharding的原因包括:
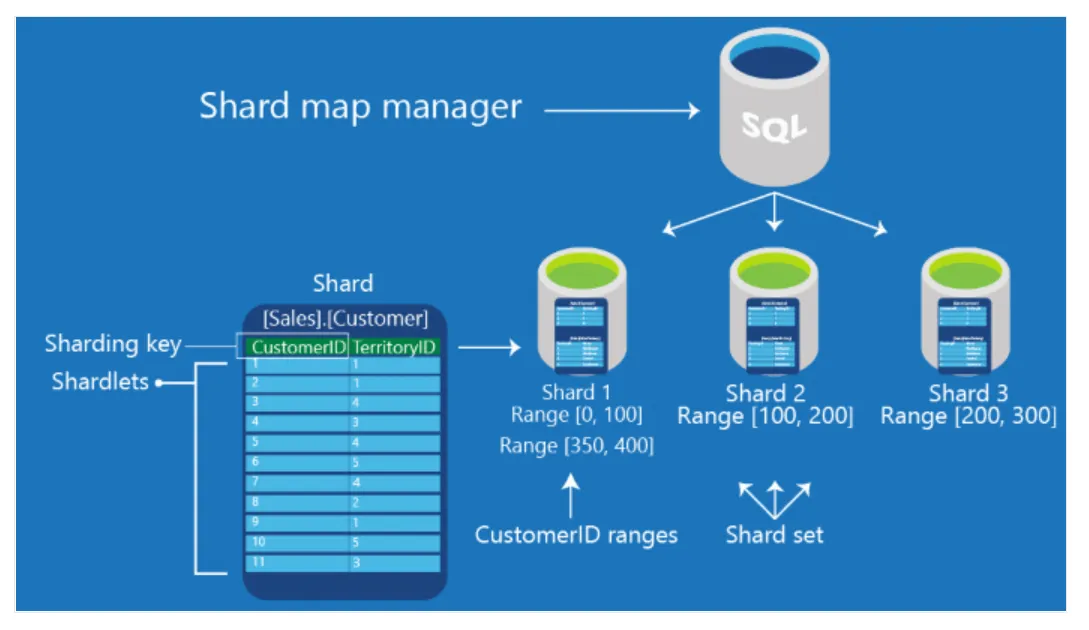
上圖呈現使用shard map manager在 Azure SQL DB上scaling out DB。 shard map manager是一個特殊的DB,它維護著一個shard set中所有shard(也就是DB)的global mapping information。 Metadata允許Application根據sharding key的值連接到正確的DB。 此外,shard set中的每個shard都包含track the local shard data(稱為 shardlet)的maps。
Azure SQL 提供 Azure Elastic Database tools。 這提供了許多工具來幫助我們從Application logic在 Azure 中建立、維護和查詢sharded SQL DB。
我們在設計上要把scale-in考量進去。 重要的是,我們的Application可以在負載下降時處理scal-in。
採用適合的DB擴展策略
下表列出了在選擇Vertical/Horizontal scaling之前要記住的重點。
Database的高可用度方案
若要了解 Azure SQL 中的可用性選項和功能,我們就需要了解service tier。 我們選擇的service tier將決定我們部署的DB或managed instance的底層架構。
有兩種模式:DTU 和 vCore。 這裡將重點介紹 vCore service tier及其高可用性架構。 我們可以將 DTU 模型的basic和standard tier等同於general purpose,將其Premium tier等同於Business Critical。
General Purpose
General Purpose service tier的DB和managed instance具有相同的可用性架構。下圖為一個guideline,首先考慮application和control ring。Application連接到server name,然後連接到gateway (GW),gateway將Application指向要連接的server,在 VM 上運行。對於General Purpose,primary replica將locally attached SSD 用於 tempdb。data和log file存儲在 Azure Premium Storage中,這是 locally redundant storage(一個region中的多個副本)。然後將backup file存儲在 Azure Standard Storage中,預設下為 RA-GRS。換句話說,它是globally redundant storage(在多個region有副本)。
所有 Azure SQL 都構建在 Azure Service Fabric 之上,它充當 Azure backbone。如果 Azure Service Fabric 確定需要進行failover,則failover將類似於failover cluster instance (FCI)。service fabric將尋找具有備用容量的節點並啟動新的 SQL Server instance。然後將 DB file attach上去,恢復運作,並更新gateway以將Application指向新節點。不需要virtual network or listener or updates。這個功能是內建的。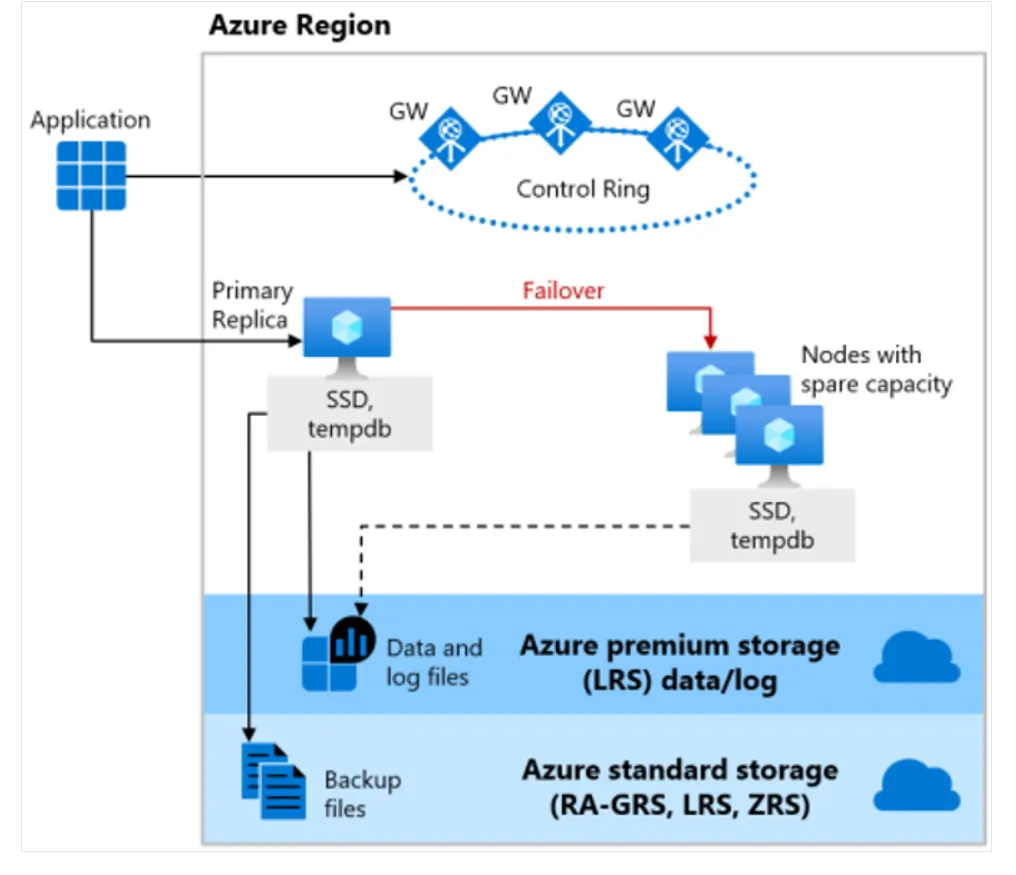
Business Critical
Business critical通常可以實現所有 Azure SQL service tiers (General Purpose, Hyperscale, Business Critical)的最高效能和可用性。 Business critical用於需要低延遲和最短停機時間的mission-critical applications。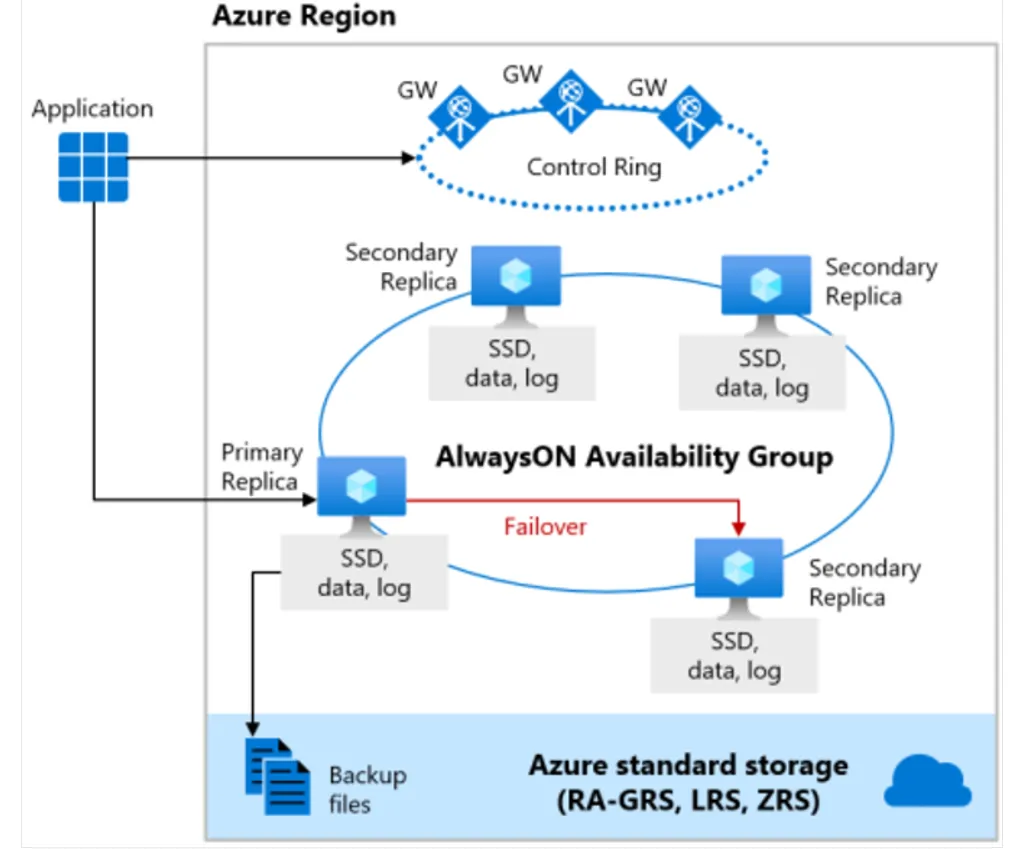
使用Business Critical就像在背景部署 Always On availability group(AG)。與eneral Purpose tier不同,在Business Critical中,data 和log file都在direct-attached SSD 上運作,這降低了network latency。 (General Purpose使用 remote storage。)在這個 AG 中,有三個secondary replicas。其中一個可用作read-only endpoint(無需額外收費)。當至少有一個secondary replicas強化了其transaction log的異動時,transaction 可以完成commit。
使用其中一個secondary replicas進行Read scale-out支援session-level consistency。因此,如果read-only session在replica無法使用導致連接錯誤後重新連接,它可能會被重導向到與 read-write replica不是 100% 最新的replica。同樣,如果Application使用read-write session寫入資料並立即使用read-only session讀取資料,則最新資料可能不會立即在replica上讀得到。資料延遲是因為非同步transaction log redo operation。
如果發生任何類型的故障並且service fabric確定需要failover,則failover到secondary replica會很快,因為這個secondary replica已經存在並且附加了資料。在failover中,我們不需要listener。即使在failover之後,gateway也會將我們的connection重定向到主節點。這個切換發生得很快,然後service fabric負責啟動另一個secondary replica。
Hyperscale
Hyperscale service tier只有可以在 Azure SQL DB使用。 這個service tier具有獨特的架構,因為它使用分層式快取和頁面伺服器,以擴充快速存取資料庫頁面的能力,而不需要直接存取資料庫檔案。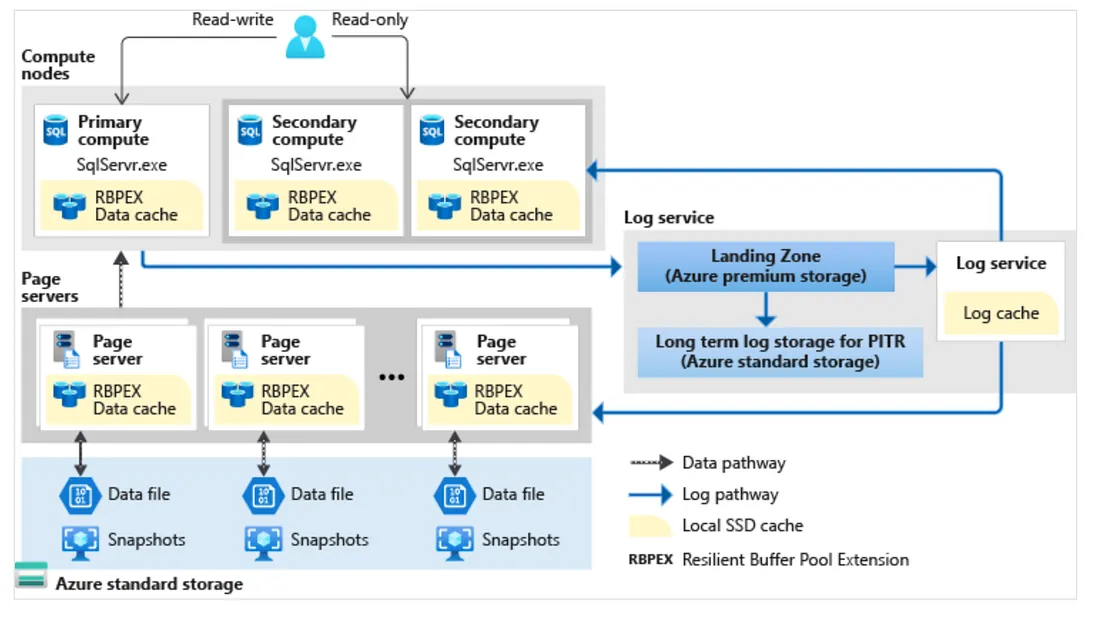
由於此架構使用成對的page servers,因此我們可以水平擴展以將所有資料放在caching layers中。這種新架構還支援高達 100 TB 的DB。因為它使用快照,所以無論大小如何,都可以進行幾乎即時的DB備份。DB restores需要幾分鐘而不是幾小時或幾天。我們還可以在一定時間內scale up or down 以乘載我們的工作負載。
log service用於提供replica和page server。當log service強化landing zone時,Transactions可以commit。因此,commit不需要secondary compute replica的consumption change。與其他service tier不同,我們可以確定是否需要secondary replicas。我們可以配置零到四個secondary replicas,它們都可以用於read-scale。
與其他service tier一樣,如果service fabric確定需要,則會發生automatic failover。但回復時間將取決於secondary replicas的存在。例如,如果我們沒有replica並且發生failover,則場景將類似於General Purpose service tier:service fabric首先需要找到備用容量。如果我們有一個或多個replica,則回復速度更快,並且更接近於Business Critical service tier的回復。
Business Critical 為具有需要低延遲的small log writes的工作負載保持最高效能和可用性。但是Hyperscale service tier允許我們有更高的log throughput(以 MB/second計),提供最大的DB大小,並提供多達四個secondary replicas以實現更高level的read scale。因此,當我們在兩者之間進行選擇時,我們要考量的是我們workload。
Geo-replication 與 auto-failover groups
選擇service tier(並在適用時考慮Availability zone)後,我們可以考慮一些其他options來取得read-scale或failover到另一個region的能力:geo-replication 與auto-failover groups。 在on-premises SQL Server 中,設定這些configuration中的任何一個都需要大量的計劃、協調和時間。
對於Geo-replication 與auto-failover groups,只需在 Azure portal中點幾下或在 PowerShell/Azure CLI 中執行一些命令即可進行配置。
Data at rest / in transit / in use的資料安全設計
如果我們是DBA,幫助確保 Azure SQL DB的環境安全。 假設我們是一家電商,將電話號碼、地址和信用卡等客戶資料存儲在託管的 Azure SQL DB中。 我們可以實施什麼解決方案來防止未經授權的人來存取資料呢?
按資料敏感性和業務影響對存儲的資料進行分類有助於組織確定與資料相關的風險。 在這裡,我們將詳細了解不同的資料狀態和加密模式。
良好資料保護的三個基本原則是:
大型組織、政府和軍事單位一直在使用資料分類來管理資料的完整性。 資料分類的結果是metadata,使我們能夠將資料標記為:
資料分類後,可以對分成較高等類資料實施資料保護措施。 在這裡中,我們將探討結構化資料的資料加密。
資料存在於三種基本狀態之一 :data-at-rest, data-in-motion, data-in-process。
在下表中,我們可以看到資料的狀態和可以實現的加密方法。
PS:
縱深防禦是一種採用分層方法來減緩主要在獲取未經授權的資訊存取攻擊策略。
 不明
不明
